900 元闲鱼组了一台 NAS + AI 小服务器:能跑模型,也真的有坑
3 月 1 日,我把家里的 NAS 升级了一次。
之前用的是蜗牛星际,作为入门 NAS 其实挺经典:便宜、够折腾,也能跑一些基础服务。但用久了之后问题就很明显了:4 盘位已经不太够我继续塞硬盘和折腾了。
我现在的需求已经不只是存文件、备份照片、跑几个 Docker 服务,还想顺便跑点本地小模型、TTS 语音合成,甚至做一些 LoRA 训练前的数据集预处理。
全新硬件看了一圈,预算很快就上去了。于是我把目标放到了闲鱼二手硬件上,最后花了 916 元,不含硬盘和内存,组出了一台带 8+4 盘位(8 个 3.5 寸硬盘位 + 内置 4 个 2.5 寸盘位)、搭配 Tesla P4 8GB 的 NAS / AI 小服务器。
系统方面,我这台机器跑的是 fnOS。传统 NAS 比较常见的文件存储、照片备份、影音管理这些功能就不展开讲了,这篇主要记录它作为一台低成本 NAS + 本地 AI 小服务器,到底能做哪些更折腾一点的事情。
先说结论:
这不是一台真正意义上的高性能 AI 服务器,也不是推荐大家无脑照抄的"神机"。
但如果你手里有一些闲置硬件,又愿意折腾二手配件、散热、驱动和 Docker,它确实能用很低的成本,把 NAS、本地 AI、TTS、数据集预处理这些事情整合到一台机器里。
一、硬件配置:主机部分 916 元
这套机器的配件基本都来自闲鱼。
| 配件 | 型号 | 价格 |
|---|---|---|
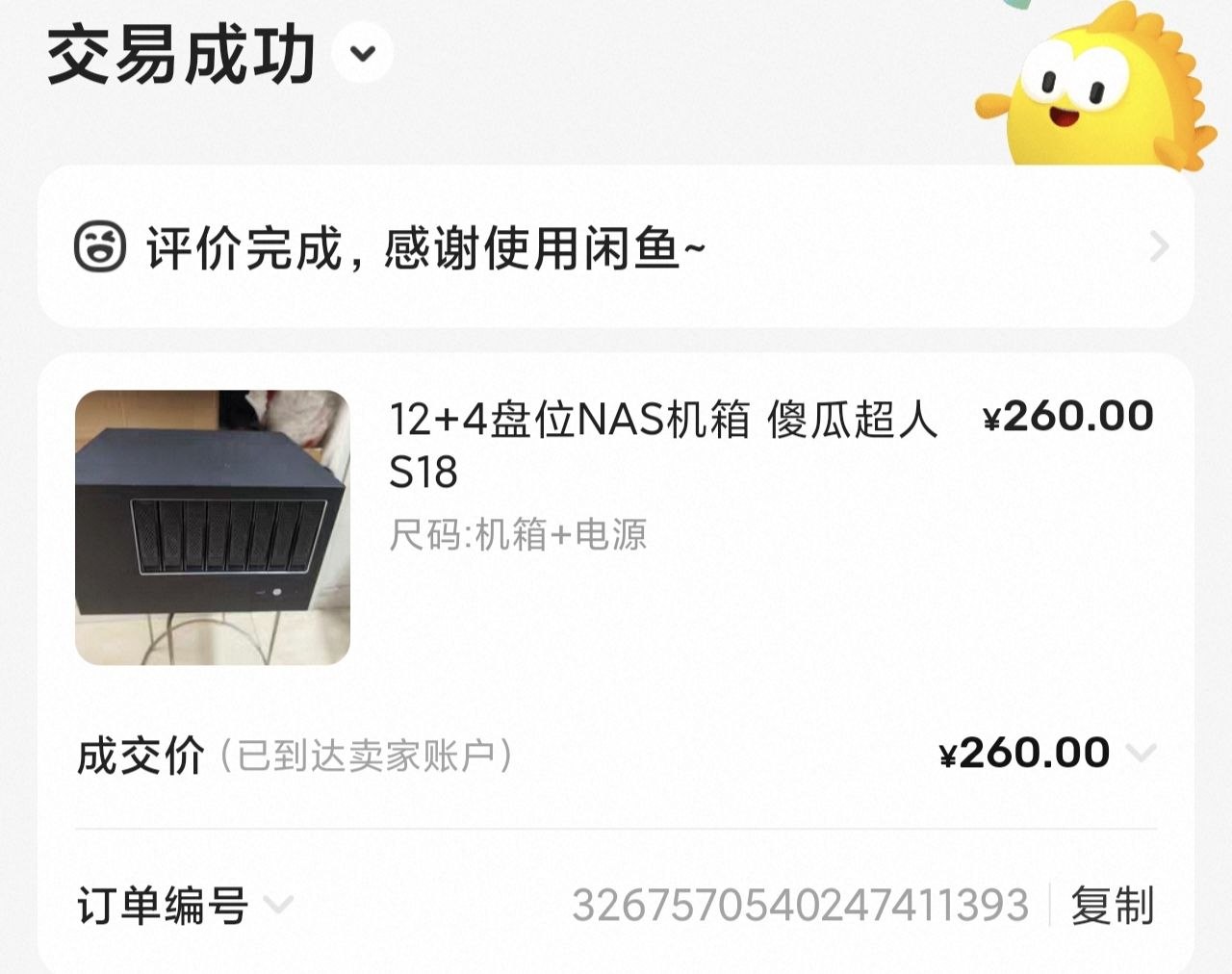
| 机箱 + 电源 | 傻瓜超人 S18(8 个 3.5 寸 + 内置 4 个 2.5 寸盘位) | ¥260 |
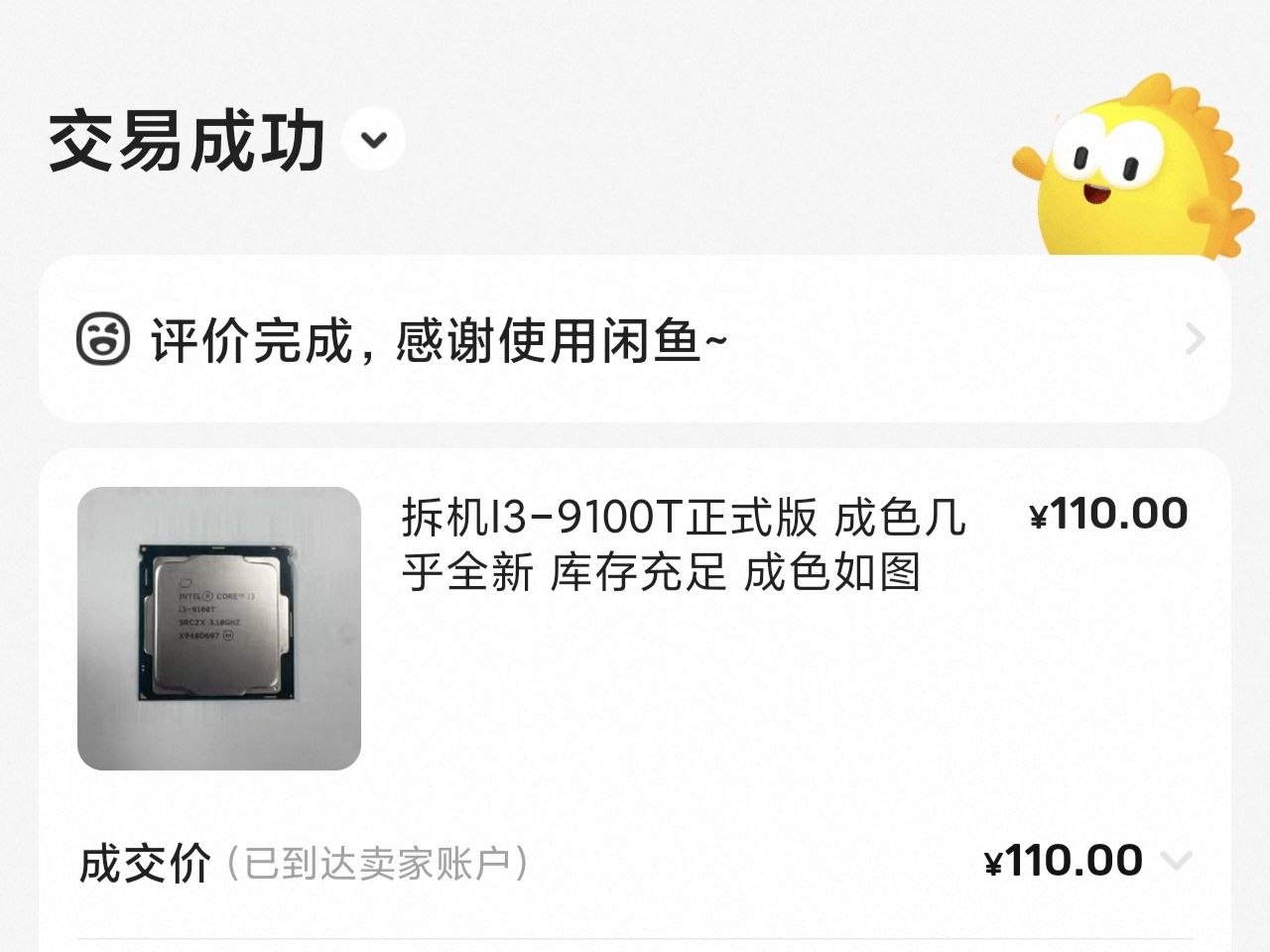
| CPU | Intel i3-9100T 拆机正式版 | ¥110 |
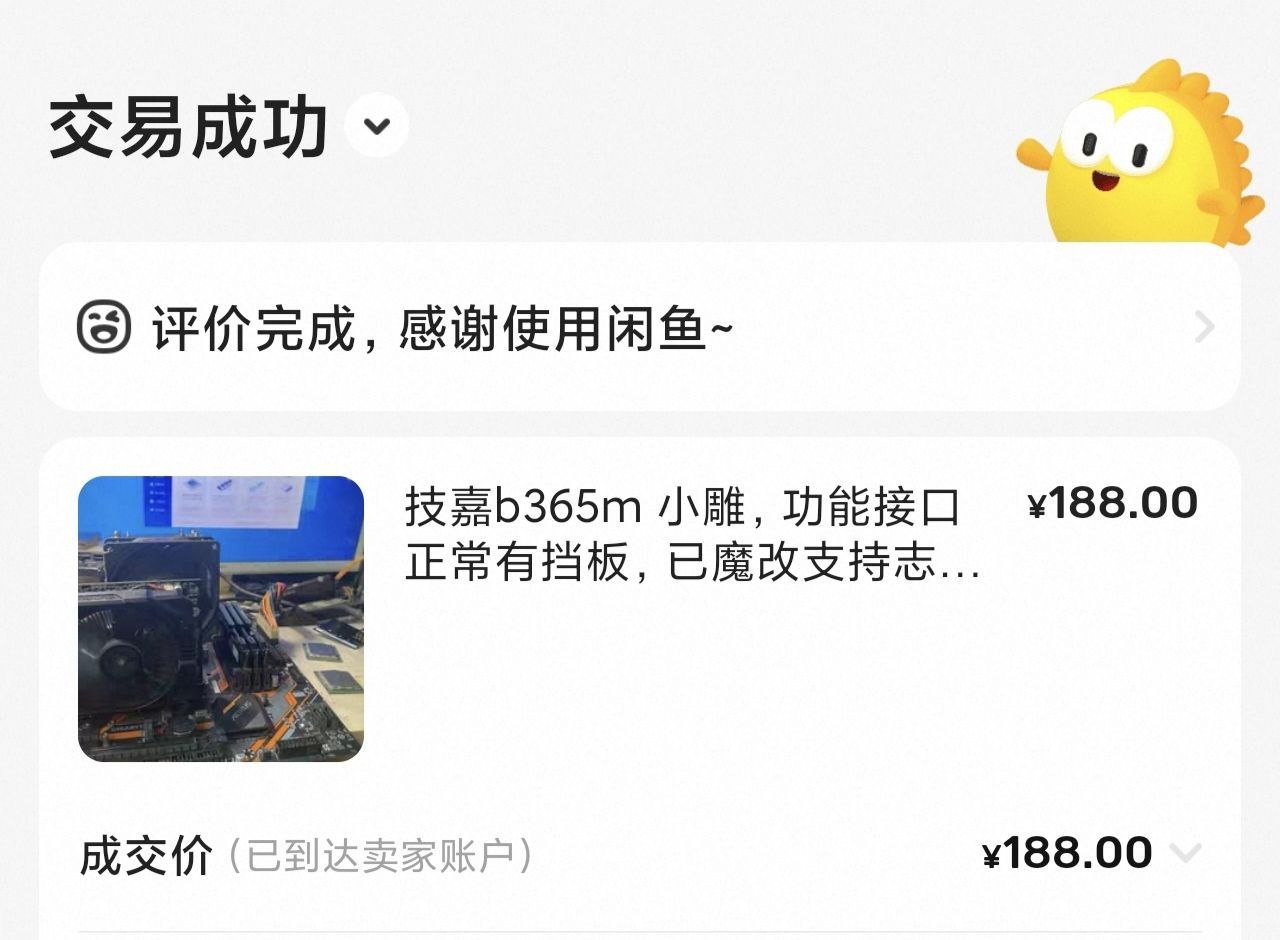
| 主板 | 技嘉 B365M 小雕(魔改支持志强) | ¥188 |
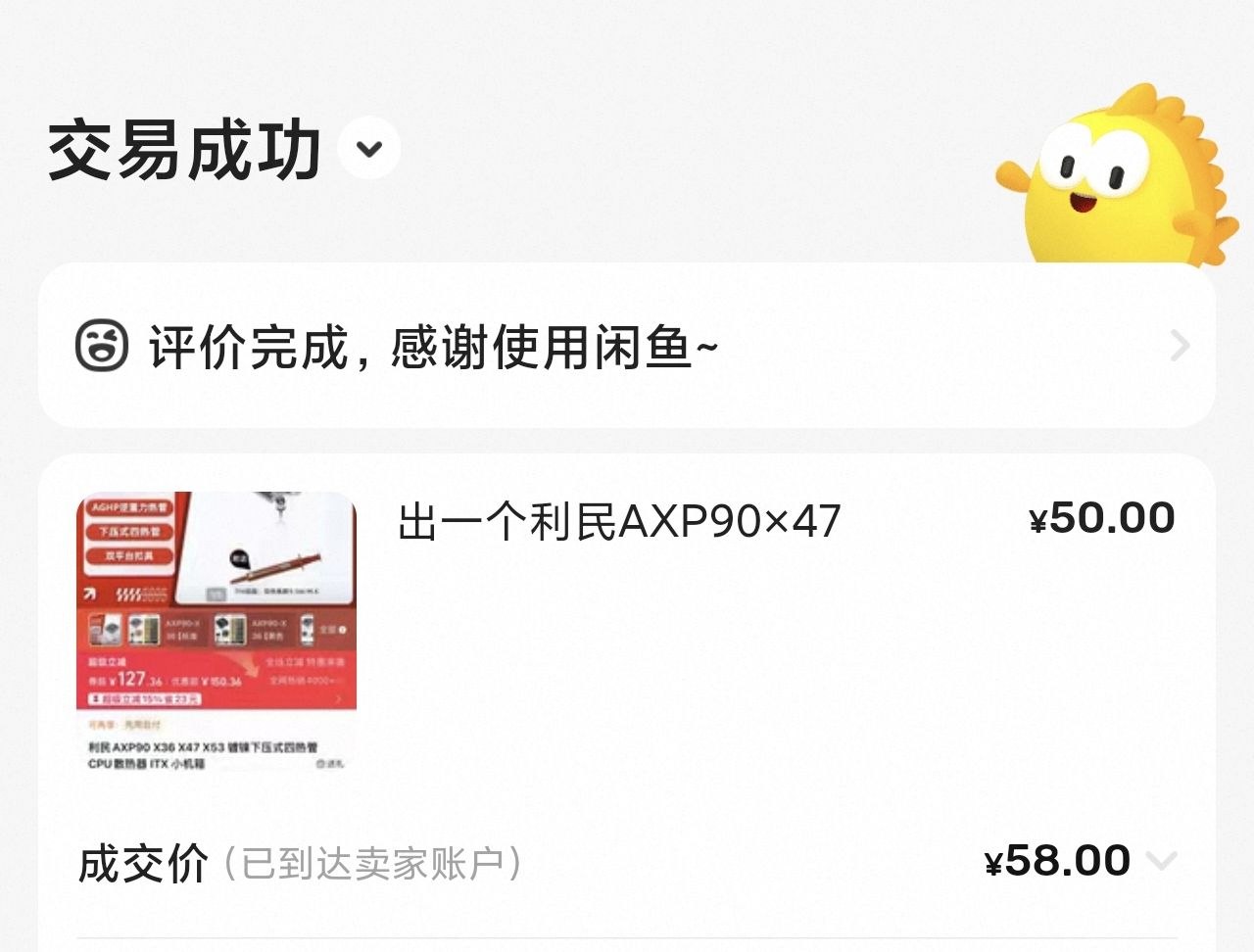
| 散热器 | 利民 AXP90×47 | ¥58 |
| 显卡 | Tesla P4 8GB | ¥300 |
| 合计 | 不含硬盘和内存 | ¥916 |
这里必须强调一下:916 元是不含硬盘和内存的价格。
NAS 真正贵的地方往往不是主机本体,而是硬盘和内存。尤其是现在内存价格不合适的时候,如果全部重新购买,整套方案的成本会被明显拉高。
所以更准确地说,这是一套"900 元左右搭出 NAS + 轻量 AI 推理平台"的方案,而不是完整 NAS 总成本。
几件配件里,我最看重的是两点:
第一,傻瓜超人 S18 是 8+4 盘位:8 个 3.5 寸硬盘位,加上内置 4 个 2.5 寸盘位,比我之前的 4 盘位蜗牛星际更适合继续扩展。
第二,技嘉 B365M 小雕有双 M.2 位。对 NAS 来说,这点挺实用:后面可以用来放系统盘、缓存盘,或者把一些容器、数据库、AI 服务的数据放到 SSD 上,减少机械硬盘的频繁读写。
第三,Tesla P4 虽然是老的数据中心卡,但 300 元左右能买到 8GB 显存,用来跑小模型、TTS、Embedding 和一些图片预处理任务,性价比还是不错的。
不过 Tesla P4 也有一个非常明显的坑:它原本是服务器被动散热卡,不能完全按普通消费级显卡的思路来装。
我这张卡是卖家已经加装了两个小风扇,所以散热条件比裸卡好一些。否则如果直接把被动散热版 Tesla P4 塞进普通机箱,满载时温度会很难看。NAS 又是长期运行设备,所以这种卡即使便宜,也一定要认真确认散热方案。
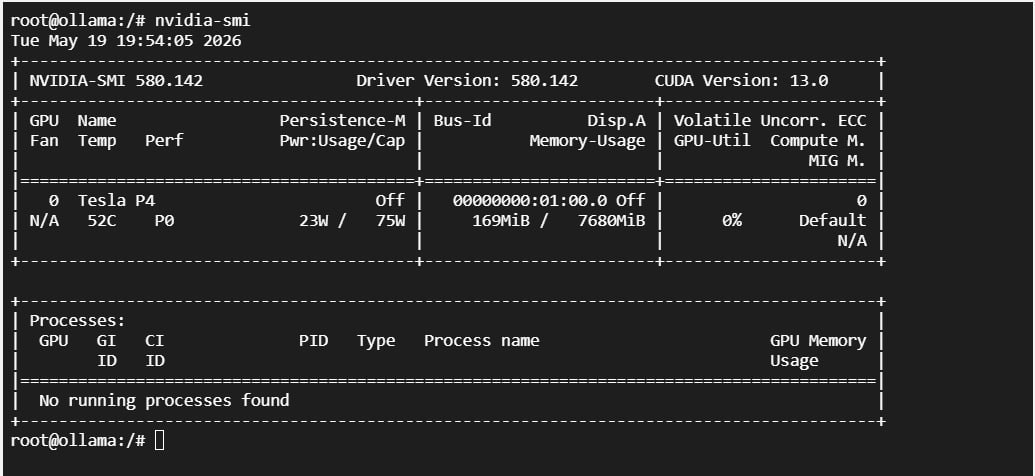
购买凭证:
装机后 nvidia-smi 验证:
二、它现在到底在干什么?
很多人一听本地小模型,第一反应可能是:
参数这么小,能有什么用?
如果只拿它和云端大模型比复杂推理、代码能力和长上下文,那它当然不占优势。
但如果把它放进具体工作流里,它其实能做很多实事。
目前这台机器主要承担这些任务:
- NAS 文件存储;
- 跑一些常驻 Docker 服务;
- 本地测试 4B / 7B 级别小模型;
- 辅助 ComfyUI 生图提示词书写;
- 做本地翻译和文本整理;
- 给 Agent 提供向量检索能力;
- 跑中文 TTS 语音合成;
- 接入 Agent、小智、有声书等语音场景;
- 做 LoRA 训练前的数据集预处理。
对我来说,它最有价值的地方不是"本地模型有多聪明",而是:
把大量重复、辅助、前处理类任务留在本地完成,需要大显存的时候,再把整理好的数据上传到服务器。
这比单纯问本地模型几个问题实用得多。
三、本地小模型的几个真实用途
1. ComfyUI 生图提示词辅助
生图的时候,提示词经常要反复调整。
人物、服装、光影、构图、镜头、背景、风格这些内容,如果全部手写会很麻烦。
本地小模型可以用来做中文描述转英文提示词、提示词扩写、风格词补全、负面提示词整理。
它不一定能一次写出顶级提示词,但可以快速给出基础稿,后面再人工微调。
这类任务不太需要特别强的推理能力,更需要随时可用、响应快、成本低,所以很适合本地模型。
2. 本地翻译和文本整理
一些英文模型说明、README、报错信息、配置说明,也可以交给本地模型处理。
云端大模型当然更强,但很多时候只是看个大概意思,或者整理一下参数说明,没必要每次都走外部 API。
本地模型的优势是没有额度焦虑,也不用担心频繁调用 API 的成本。
3. Agent 使用的向量模型
除了聊天模型,我还部署了 Embedding / 向量模型。
这类模型不负责直接回答问题,而是给 Agent 做检索和记忆用。
比如文档切片后做向量化、本地知识库检索、Agent 查找历史资料、给自动化工具提供语义搜索能力。
这个方向很适合常驻 NAS,因为向量模型通常不需要特别大的显存,只要部署稳定,就可以长期挂在本地给各种工具调用。
4. LoRA 训练前的数据集预处理
这是我觉得最实用的场景之一。
真正训练 LoRA 之前,最麻烦的不是点一下训练按钮,而是准备数据集。
图片需要先做识别、自动打标、去重、低质量筛选、内容合规筛查、分类、生成 caption / tag 文本。
这些步骤如果全部放到租来的 GPU 服务器上做,其实很浪费钱。
服务器租金是按时间算的,你在上面慢慢整理图片、打标、筛选,本质上是在花钱做前处理。
更合理的方式是:
在本地 NAS 上先把图片识别、打标、去重、筛选都处理好,整理成可以直接训练的数据集。真正需要大显存的时候,再把干净的数据集上传到服务器训练 LoRA。
这样可以减少服务器空转时间,也能省下一部分租用成本。
四、跑模型实测:速度可以,边界也明显
我用 Ollama 部署了一些 Gemma4 社区微调模型,包括 4B 级别的小模型,以及配套的 Embedding 模型。
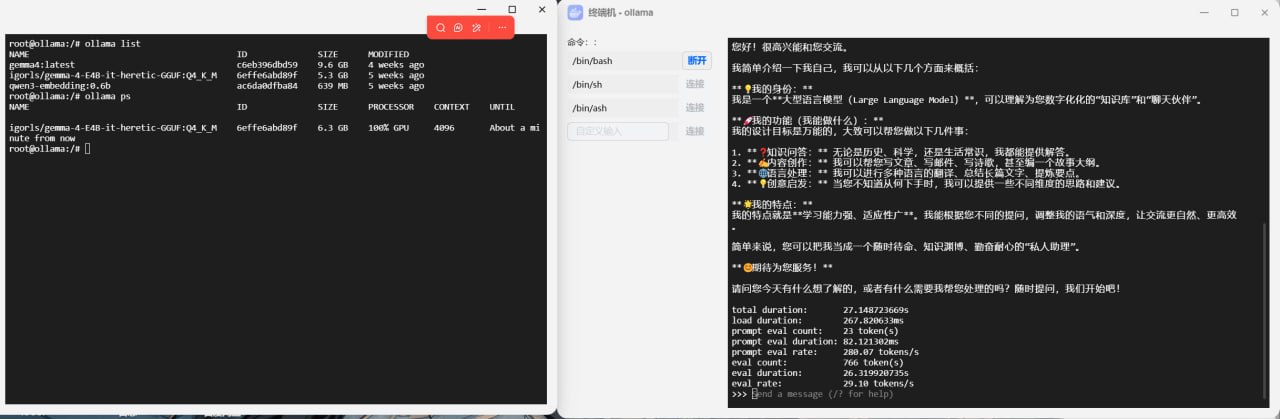
这类模型最大的优点是跑得快、占用低、本地部署门槛低。
但缺点也很现实:复杂推理不稳定,容易过度解释,对隐含条件理解差。
我用一个小常识题测试过:
我把钥匙放进抽屉,然后离开房间,回来后我想开门,应该先找什么?
正常思路应该是:钥匙在房间里的抽屉中,而人已经在房间外面,所以重点不是找抽屉,而是想办法先进入房间,或者找备用钥匙。
实际模型回答得很认真,也分析了很多内容,但最后重点跑偏了,甚至把答案引到了"先找抽屉的把手"。
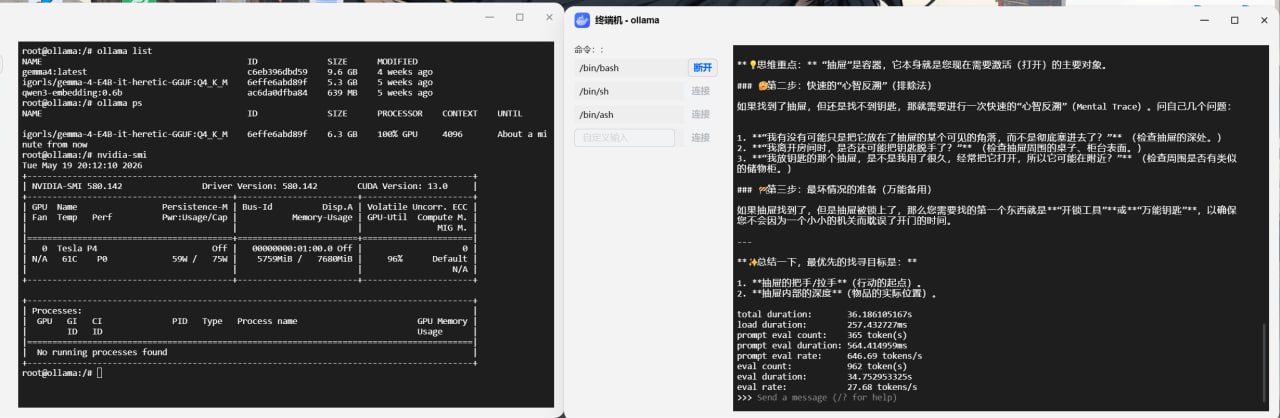
这就是小模型很典型的问题:
它不是完全不会思考,而是经常把简单问题复杂化,然后在复杂化的过程中跑偏。
这次测试里,它生成了 962 个 token,速度大约是 27.68 tokens/s,总耗时 36 秒。
所以我对本地小模型的定位不是"代替云端大模型",而是:
让 NAS 变成一个随时可用、低成本、能处理大量重复任务的本地 AI 工具箱。
五、TTS:AngeVoice 已经能接入真实场景
除了跑小模型,这台机器还跑了我自己的 TTS 项目:AngeVoice Studio。
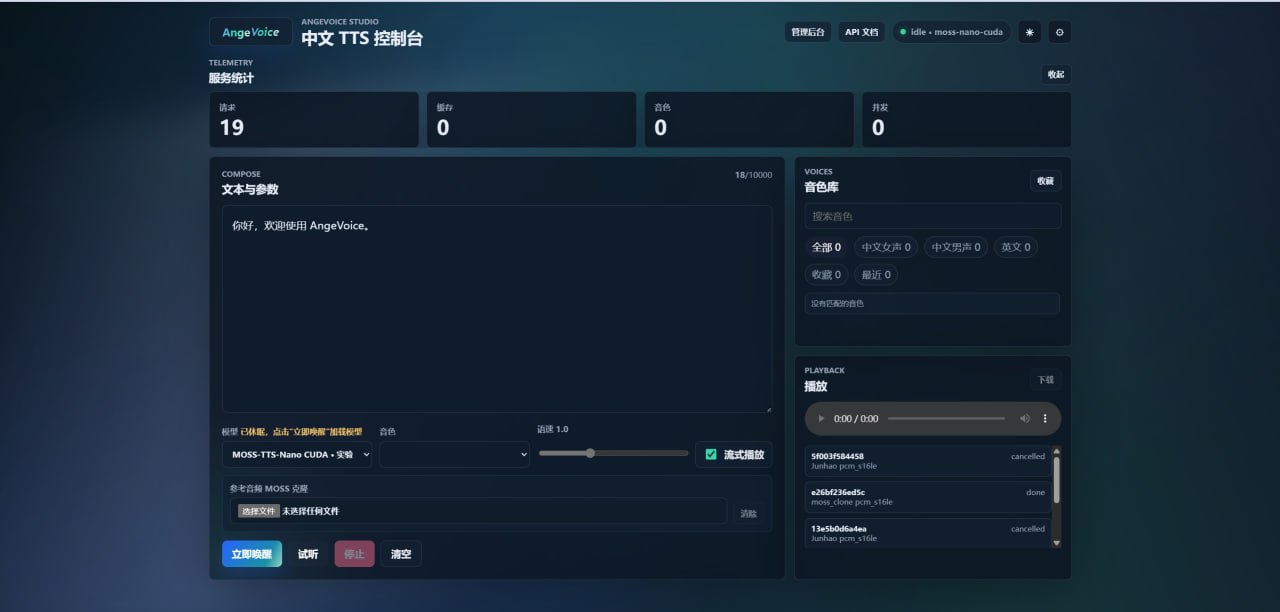
它是一个中文语音合成控制台,支持音色选择、语速调节、Web 前端操作、流式播放、参考音频克隆和本地 API 调用。
基于当前已实现能力,后续可以继续尝试接入这些方向:
- 接入 Agent,让文字回复变成语音;
- 接入类似"小智"的语音助手;
- 做有声书生成;
- 做本地语音播报;
- 测试参考音频克隆和流式播放。
这里我也做了一个对 NAS 用户比较重要的功能:
空闲 10 分钟后自动卸载模型,释放显存;下次调用时再自动唤醒加载。
因为 NAS 是长期在线设备,如果模型一直常驻,占用显存和功耗都不太合适。
不过本地 TTS 也有边界。
为了追求实时对话,模型不能选得太大。参数更大的模型可能音质更好、情感更自然,但延迟也会更高,对显存和 CPU 的压力也更大。
所以实时语音对话更适合优先保证延迟和稳定性;有声书这种长文本场景,可以接受慢一点,换取更稳定的输出。
后续我更想优化的是语音质量和可控性,比如模型分词器、多音字词典、自定义词典、专有名词和角色名读音,以及长文本断句和语气。
六、这套方案适合谁?
我觉得它适合这几类人:
- 想低成本组 NAS;
- 手里有闲置内存、硬盘或旧平台;
- 愿意折腾闲鱼二手硬件;
- 想体验本地小模型、TTS、Embedding;
- 想做 ComfyUI、LoRA、Agent 相关工作流;
- 不追求极致性能,更看重性价比和可玩性。
但它不适合这些人:
- 完全不想折腾;
- 想买回来就稳定用几年;
- 对噪音、功耗、外观非常敏感;
- 希望直接跑大模型;
- 不愿意处理 BIOS、驱动、散热、Docker 问题。
这套机器最大的价值不是性能多强,而是用很低的成本,把 NAS、本地 AI、TTS 服务和数据集预处理环境整合到了一起。
七、最后说点现实的
这台机器已购配件花了 916 元,但这不代表完整 NAS 只需要 916 元。
硬盘和内存都没算进去。
你要问我内存成本怎么办?只能说,我的非主力机器正在角落里问我:
"我怎么突然少了两条内存?"
所以这套方案更适合手头本来就有一些闲置硬件的人折腾。
如果你现在从零开始,把机箱、主板、CPU、显卡、内存、硬盘全部重新买一遍,那它就不一定还算低成本了。
我的建议是:
有闲置硬件,可以折腾;缺什么补什么,可以考虑;如果所有东西都要现买,就一定要先算清楚总账。
这篇先记录到这里。
这不是一套适合所有人的方案,也不是"900 元买到全能服务器"的神话。它更适合手里本来就有一些闲置硬件,又愿意花时间折腾的人。
对我来说,这次升级最大的意义不是性能提升了多少,而是终于从 4 盘位蜗牛星际,换成了一台更适合继续扩展、也更适合本地 AI 工作流的 NAS。
评论
游客无需注册即可评论。
你提交的昵称、邮箱、网址和评论内容会保存在服务端,用于展示评论身份、接收回复及必要的安全审计。
浏览器会本地保存已填游客信息和评论草稿,方便下次免填。
回复提醒会通过站内消息和邮件通知。